Type 2: the metacognitive stage
The main goal of ReMeta is making inferences about metacognitive noise and biases. Metacognitive noise is any noise that occurs after the computation of the type 1 decision variable (). Metacognitive biases describe under- and overconfidence.
While coming with sensible defaults, ReMeta allows the modeler to decide at which point in the hierarchy such sources of noise and bias may occur.
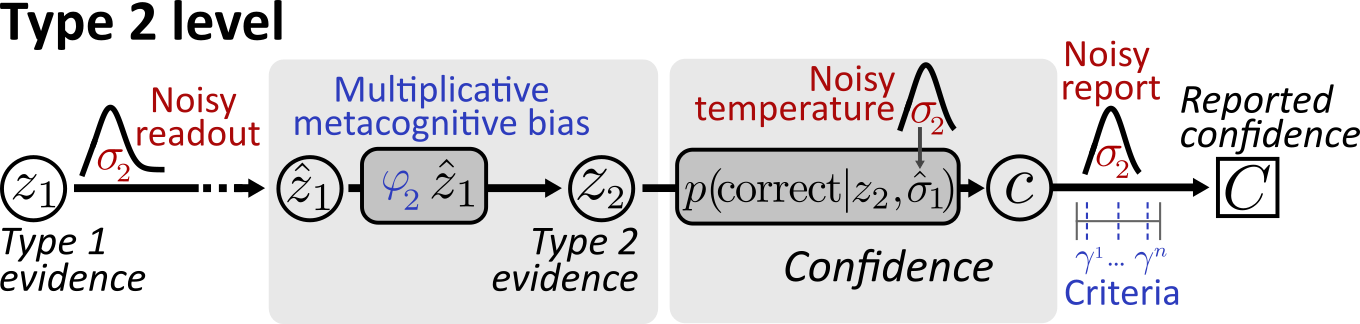
ReMeta considers three sources of metacognitive noise:
| How to enable | What it is | Reference | |
|---|---|---|---|
| Noisy report (default) | cfg.type2_noise_type = 'report' | Noisy confidence report | Shekhar & Rahnev (2021) |
| Noisy readout | cfg.type2_noise_type = 'readout' | Noisy readout of type 1 evidence | Guggenmos (2022) |
| Noisy temperature | cfg.type2_noise_type = 'temperature' | Noisy estimate of one’s own type 1 noise | Boundy-Singer et al. (2022) |
At this point, these noise sources are mutually excluside, i.e. the modeler has to make an assumption about the dominant source of metacognitive noise (or do systematic testing).
ReMeta is fundamentally built on the assumption that observers computed as the probability that the type 1 decision was correct, i.e.
in case of normal type 1 noise and
in case of logistic type 1 noise. The assumption is required to compute metacognitive biases, as otherwise one would have to ask: under/overconfident relative to what?
In ReMeta’s parameterization, corresponds to the standard deviation of the underlying type 1 noise distribution.
Confidence is represented on a scale from 0, corresponding to (i.e. guessing), to 1, corresponding to . Mathematically this is a simple transformation:
For this reason, confidence ratings should be passed as normalized values between 0 and 1 to ReMeta.
Default parameters¶
Type 2 noise¶
| Parameter | Symbol | How to enable | Default | Possible values |
|---|---|---|---|---|
type2_noise | cfg.param_type2_noise.enable = True | True | True |
While the the nature of type 2 metacognitive noise is up to the researcher ('report', 'readout' or 'temperature'), the type2 noise parameter cannot be disabled, as a probabilistic aspect is required for maximum likelihood estimation.
The difference between the three sources of metacognitive noise is not just conceptual. Each noise source has a clear computational signature, as seen below:
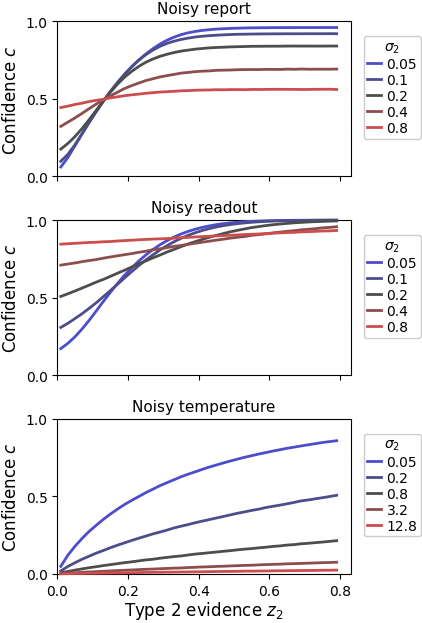
In all three cases, higher metacognitive noise () leads to a shallower relationship between type 1 evidence and confidence , i.e. to reduced metacognitive sensitivity. Howvever, for very high metacognitive noise, the noisy-report model predicts average confidence for all type 1 evidence, the noise-readout model maximum confidence, and the noisy-temperature model minimal confidence.
Which noise type is dominant for human observers is currently unknown. For an individual study, we recommend checking out the type 2 likelihod for each of the architectures to make an informed decision.
Type 2 noise distribution¶
Likewise unknown is the precise distributional nature of metacognitive noise. In ReMeta, the distribution can be set via
cfg.param_type2_noise.distribution = '...'Available options:
cfg.type2_noise_type | Default | Available choices for cfg.type2_noise_dist |
|---|---|---|
'report' | 'beta_mode' | 'beta_mean_std', 'beta_mode_std', 'beta_mode', 'truncated_normal_mode_std', 'truncated_normal_mode', 'truncated_gumbel_mode_std', 'truncated_gumbel_mode', 'truncated_lognormal_mode_std', 'truncated_lognorm', 'truncated_lognormal_mode', 'truncated_lognormal_mean' |
'readout' / 'temperature' | 'lognormal_mode_std' | 'lognormal_median_std', 'lognormal_mean', 'lognormal_mode', 'lognormal_mode_std', 'lognormal_mean_std','gamma_mode_std', 'gamma_mean_std', 'gamma_mean', 'gamma_mode', 'gamma_mean_cv','betaprime_mean_std','truncated_normal_mode_std', 'truncated_normal_mode','truncated_gumbel_mode_std', 'truncated_gumbel_mode' |
The suffices _mode and _mean indicate a parameterization of the distribution which preserves the mode and mean, respectively. The suffices _std and _cv indicate a parameterization such that type2_noise (i.e. ) corresponds to the standard deviation and the coefficient of variation, respectively.
A paper is still to be written about the evidence and validity of different metacognitive noise distributions. For now, the default choices (beta_mode / lognormal_mode_std) in ReMeta are motivated by the following criteria:
Analytical parameterization possible (=computationally efficient)
Good performance on our own test datasets (though these results not yet published)
Evidence from other groups in favor of the lognormal distribution as opposed to e.g. a Gamma distribution 13.
Parameter
type2_noisecorresponds roughly to the standard deviation of the noise distribution, for ease of interpretability across models.
import remeta
import numpy as np
%load_ext autoreload
%autoreload 2The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload
The default distribution for noisy-report models 'beta_mode' follows the standard mode-concentration parameterization of the Beta distribution:
In this parameterization, is not exactly the standard deviation of the Beta distribution, but a reasonable approximation.
The default distribution for noise-readout/temperature models 'lognormal_mode_std' is an exact parameterization in terms of standard deviation and mode:
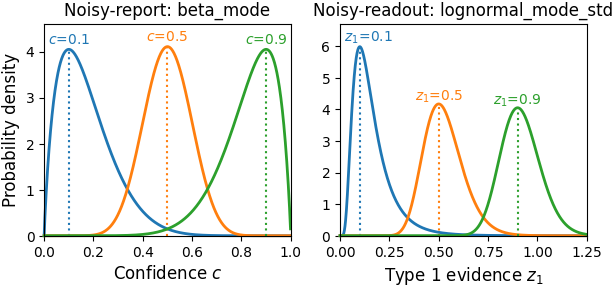
Type 2 noise distributions with
Type 2 criteria¶
| Parameter | Symbol | How to enable | Default | Possible values |
|---|---|---|---|---|
type2_criteria | cfg.param_type2_criteria.enable = True | True | False, True |
The majority of confidence scales used in the field are based on a discrete scales, e.g. 1=very unsure, 2=unsure, 3=sure, 4=very sure. Thus, participants in such studies need to apply criteria to map a (possibly) continuous internal estimate to a finite number of response options.
In ReMeta, such criteria are fitted at the last stage of the process. Specifically, it is assumed that observers have a continuous internal estimate of confidence (range 0-1) and apply a set of criteria to this internal estimate.
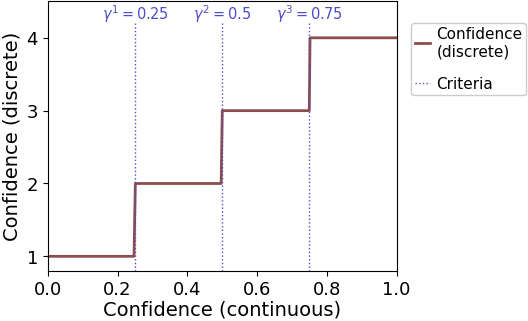
The number of fitted confidence levels is passed to ReMeta during the fit command (fit(stimuli, choices, confidence, n_ratings=X)).
We generally recommended to fit confidence criteria also for continuous confidence scales. Even for continuous scales, observers tend to have idiosyncratic ways of using different sections of the scale and this is often best accounted for through confidence criteria. For continuous scales, we recommend to pass n_ratings=4 to the ReMeta fit() method.
Criterion and confidence bias¶
If confidence data are fitted with type2_criteria enabled, ReMeta will compute an average criterion bias which could be considered an estimate of the overall metacognitive bias.
As an example, let’s generate data in which each of the observers three confidence criteria [0.35, 0.5, 0.85] is shifted by 0.1 from Bayes-optimal confidence criteria [0.25, 0.5, 0.75].
params = dict(type1_noise=0.5, type1_bias=0, type2_noise=0.25, type2_criteria=[0.35, 0.6, 0.85])
np.random.seed(0)
sim = remeta.simulate(params=params)The red line below indicates the new mapping from internal (continuous) confidence to reported (discrete) confidence, relative to the Bayes-optimal mapping (blue line):
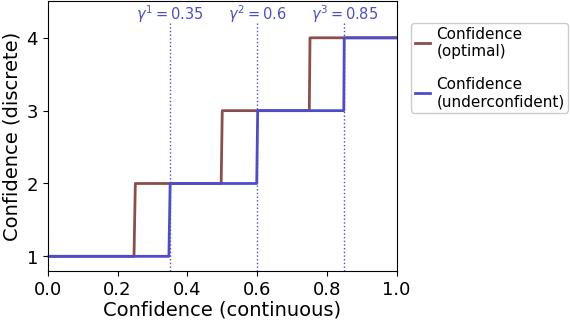
Positive criterion shifts are reflected in underconfident confidence reports, since higher internal confidence is required for each discrete confidence rating.
We now fit ReMeta to this dataset (using default settings, i.e. no remeta.Configuration is required, though we pass the true parameters for reference).
rem = remeta.ReMeta(true_params=params)
rem.fit(sim.stimuli, sim.choices, sim.confidence, n_ratings=4)
result = rem.summary()If type 2 criteria are fitted, the ReMeta summary contains a key 'type2_criteria_bias' in result.params_extra which reflects just that:
print(f"Criterion bias: {result.params_extra['type2_criteria_bias']:.3f}")Criterion bias: 0.098
Thus the criterion bias was estimated to be +0.089 (ground truth was +0.1). The confidence bias is just the negative of the criterion bias and is also part of params_extra:
print(f"Confidence bias: {result.params_extra['type2_criteria_confidence_bias']:.3f}")Confidence bias: -0.098
Negative and positive confidence biases correspond to under- and overconfident observers, respectively.
In ReMeta, the type 2 criterion bias is computed as a weighted average deviation of estimated criteria from Bayes-optimal criteria . The weights are the uncertainty estimates of each criterion, such that more reliabily estimated criteria contribute stronger to the bias computation. In practise, we use the full covariance matrix for this weighted bias to also consider the correlation between criterion uncertainties:
where is the inverse sampling covariance matrix of the criteria.
However, there’s a catch...
While computing a confidence bias in this way serves for a first approximation, these bias estimates are post-hoc, i.e. they are not part of the process model and thus are likely (sic) biased.
This is a real dilemma in confidence modeling: human participants clearly apply idiosyncratic confidence criteria in their responses and those should be modeled; on the other hand, modeling those criteria makes an estimation of metacognitive biases very challenging.
The two parameters described below (type2_evidence_bias and type2_confidence_bias) make an attempt at incorporating bias parameters within the process model.
Additional parameters¶
Metacognitive evidence bias¶
| Parameter | Symbol | How to enable | Default | Possible values |
|---|---|---|---|---|
type2_evidence_bias | cfg.type2_evidence_bias.enable = True | False | False, True |
Type 2 criteria account for metacognitive biases that occur at the level of the confidence report, i.e. when observers map an internal sense of confidence to an external confidence scale. The idea of a metacognitive evidene bias is that biases may also occur at an earlier stage - specifically for the internal representation of metacognitive evidence , which is algorithmically reflected as follows (assuming normal type 1 noise):
The effect of on confidence is shown in the figure below.
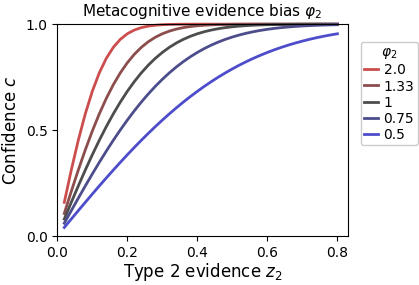
In theory, the metacognitive evidence parameter is separable from the effects of type 2 criteria ; in practice — with limited sample size — they might trade of each other.
Metacognitive confidence bias¶
| Parameter | Symbol | How to enable | Default | Possible values |
|---|---|---|---|---|
type2_confidence_bias | cfg.type2_confidence_bias.enable = True | False | False, True |
It seems tempting to model a metacognitive bias as a parameter that systematically affects all confidence criteria. For instance, consistent withe notion of an additive and multiplicative criteriorn bias above, one could think of describing metacognitive biases as a parametric deviation from Bayes-optimal criteria (e.g. ). Indeed, the evidence bias above plays a role similar to .
Additive shifts, in turn, are always tricky, since they need to be accompanied by clipping (e.g., neither evidence nor confidence can be below 0). ReMeta offers one additional metacognitive bias parameter that circumvents clipping issues: the confidence bias :
is a power-law parameter which ensures that confidence remains between 0 and 1. Such a parameter has little biological plausibility, but it is mathematically convenient. To some very rough approximation it resembles an additive shift, with appropriate asymptotic behavior at the confidence bounds 0 and 1.
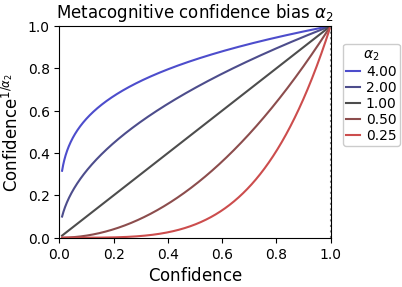
The computational signature of is clearly distinguishable from the evidence bias :
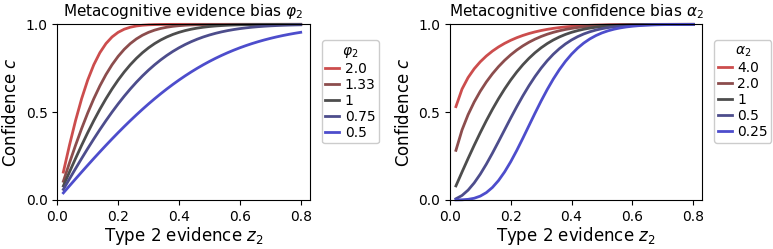
The parameters and are thus likely distinguishable in a parameter recovery analysis. Nevertheless, they have little empirical validation and may not work well with simultaneous confidence criteria. Fot this reason, and are disabled by default.
- Shekhar, M., & Rahnev, D. (2021). The nature of metacognitive inefficiency in perceptual decision making. Psychological Review, 128(1), 45–70. 10.1037/rev0000249
- Guggenmos, M. (2022). Reverse engineering of metacognition. eLife, 11. 10.7554/elife.75420
- Boundy-Singer, Z. M., Ziemba, C. M., & Goris, R. L. (2022). Confidence reflects a noisy decision reliability estimate. Nature Human Behaviour, 6(11), 1546–1558. 10.1038/s41562-022-01464-x