Getting started
Three types of data are required to fit a ReMeta model:
| Variable | Description |
|---|---|
stimuli | list/array of signed stimulus intensity values, where the sign codes the stimulus category and the absolute value encodes stimulus evidence. |
choices | list/array of choices coded as 0 (or alternatively -1) for the negative stimuli category and 1 for the positive stimulus category. |
confidence | list/array of confidence ratings. Confidence ratings must be normalized to [0; 1]. Discrete confidence ratings must be normalized accordingly (e.g., if confidence ratings are 1-4, subtract 1 and divide by 3). |
When fitting individual participants, these are 1d lists / arrays with length n_trials. When 2d lists / arrays are passed, ReMeta treats this as group data with shape n_subjects x n_trials (see Group estimation and priors).
A simple example¶
To quickly demonstrate ReMeta, we load a simple build-in dataset as follows.
import remeta
ds = remeta.load_dataset('default')----------------------------------
..Generative model:
Type 1 noise distribution: normal
Type 2 noise type: report
Type 2 noise distribution: beta_mode
..Generative parameters:
type1_noise: 0.5
type1_bias: -0.1
type2_noise: 0.3
type2_criteria: [0.25 0.5 0.75]
[extra] Criterion bias: 0.0000
[extra] Criterion-based confidence bias: 0.0000
..Descriptive statistics:
No. subjects: 1
No. samples: 2000
No. of discrete confidence levels: 4
Accuracy: 85.2% correct
d': 2.1
Choice bias: -3.9%
Confidence: 0.65
M-Ratio: 0.95
AUROC2: 0.77
----------------------------------
The output provides information how the dataset was generated and some descriptive statistics.
The dataset was generated with four stimulus intensities. The psychometric function below shows that the observer performed at around 60% correct for the lowest (and most difficult) stimulus intensity and close to perfect for the highest intensity.
remeta.plot_psychometric(ds)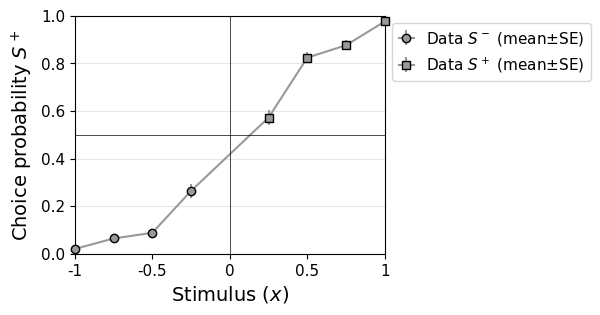
The relationship between stimulus intensity and confidence likewise reflects the bias, but also shows that the observer is less sensitive than predicted by a model without metacognitive noise. In the above descriptive statistics is visible from the low M-Ratio of 0.58.
remeta.plot_stimulus_versus_confidence(ds, model_prediction=True)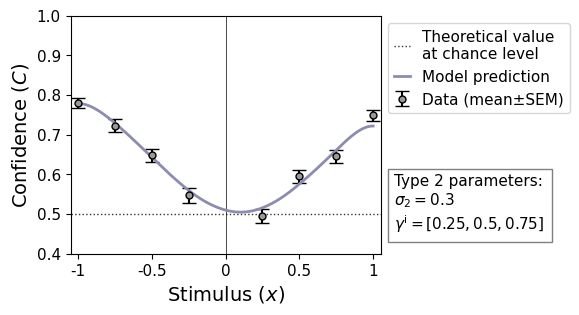
In a next step, we fit the model. Since the data were generated with the default ReMeta model, we do not need to define any other settings. We pass the Configuration option optim_type2_gridsearch=False to the ReMeta instance though, to speed up this demo.
rem = remeta.ReMeta(optim_type2_gridsearch=False)
# Confidence ratings in this simulated dataset have four discrete levels
rem.fit(ds.stimuli, ds.choices, ds.confidence, n_ratings=4)Dataset characteristics:
No. subjects: 1
No. samples: 2000
Accuracy: 85.2% correct
d': 2.117
Choice bias: -3.9%
Mean confidence: 0.648 (min: 0.125, max: 0.875)
+++ Type 1 level +++
Subject-level estimation (MLE)
.. finished (0.3 secs).
Final report
Parameters estimates (subject-level fit)
[subject] type1_noise: 0.510 ± 0.018
[subject] type1_bias: -0.099 ± 0.019
[subject] Log-likelihood: -717.84 (per sample: -0.3589)
[subject] Fitting time: 0.22 secs
Type 1 level finished
+++ Type 2 level +++
Subject-level estimation (MLE)
.. finished (173.1 secs).
Final report
Parameters estimates (subject-level fit)
[subject] type2_noise: 0.312 ± 0.047
[subject] type2_criteria: [0.278 ± 0.012, 0.505 ± 0.014, 0.738 ± 0.018]
[extra] type2_criteria_bias: 0.016 ± 0.010
[extra] type2_criteria_confidence_bias: -0.016 ± 0.010
[subject] Log-likelihood: -2938.91 (per sample: -1.469)
[subject] Fitting time: 58.13 secs
Type 2 level finished (173.1 secs)
<remeta.model.ReMeta at 0x7ceab2fac190>Since the dataset is based on simulation, we know the true parameters of the underlying generative model (see first output), which are quite close to the fitted parameters.
We can access the fitted parameters by invoking the summary() method on the ReMeta instance:
# Access fitted parameters
import numpy as np
result = rem.summary()
for k, v in result.params.items():
print(f'{k}: {np.array2string(np.array(v), precision=3)}')type1_noise: 0.51
type1_bias: -0.099
type2_noise: 0.312
type2_criteria: [0.278 0.505 0.738]
By default, the model fits parameters for type 1 noise and a type 1 bias, as well as metacognitive ‘type 2’ noise and three confidence criteria.
Enabling and disabling parameters¶
ReMeta is not “a” model, but rather a framework for several possible models. To define a model, we need make architectural decisions, but also specify the set of parameters to fit. Model specification works via the Configuration object. While there is a dedicated section for the Configuration, we will introduce it briefly here.
cfg = remeta.Configuration()For instance, we could fit the above data without a type 1 bias. To do so, we disable the corresponding parameter in the configuration.
cfg.param_type1_bias.enable = FalseThe parameters for type 1 and type 2 noise cannot be disabled, since the model needs to be probabilistic in nature to compute likelihoods.
Apart from enabling and disabling, type 1 parameters can be fitted asymmetrically, i.e. separately for each stimulus category. On the to-do-list is asymmetric fitting by response category by response category, but this is currently not possible. To active asymmetric fitting of type 1 parameters use the following logic:
cfg.param_type1_bias.asym = True| Parameter | Description | default | supported |
|---|---|---|---|
type1_noise | Type 1 noise | True | True |
type1_thresh | Sensory threshold | False | False,True |
type1_bias | Choice bias | True | False,True |
type1_nonlinear_encoding_gain | Nonlinear encoding | False | False,True |
type1_nonlinear_encoding_scale | Nonlinear encoding | False | False,True |
type2_noise | Metacognitive noise | True | True |
type2_evidence_bias | Metacognitive evidence bias | False | False,True |
type2_confidence_bias | Metacognitive confidence bias | False | False,True |
type2_criteria | Confidence criteria | True | False,True |
Each parameter in the above table can be enabled or disabled by changing the value of cfg.param_<parameterName>.enable = X.
Let’s fit the model to the same data, but this time without a type 1 bias. To let ReMeta know about our above setting cfg.param_type1_bias.enable = False, we pass the configuration instance to the ReMeta constructor:
rem = remeta.ReMeta(cfg)
rem.fit(ds.stimuli, ds.choices, ds.confidence, n_ratings=4)Dataset characteristics:
No. subjects: 1
No. samples: 2000
Accuracy: 85.2% correct
d': 2.117
Choice bias: -3.9%
Mean confidence: 0.648 (min: 0.125, max: 0.875)
+++ Type 1 level +++
Subject-level estimation (MLE)
.. finished (0.2 secs).
Final report
Parameters estimates (subject-level fit)
[subject] type1_noise: 0.518 ± 0.018
[subject] Log-likelihood: -731.36 (per sample: -0.3657)
[subject] Fitting time: 0.15 secs
Type 1 level finished
+++ Type 2 level +++
Subject-level estimation (MLE)
.. finished (211.6 secs).
Final report
Parameters estimates (subject-level fit)
[subject] type2_noise: 0.312 ± 0.048
[subject] type2_criteria: [0.272 ± 0.012, 0.498 ± 0.014, 0.732 ± 0.018]
[extra] type2_criteria_bias: 0.010 ± 0.010
[extra] type2_criteria_confidence_bias: -0.010 ± 0.010
[subject] Log-likelihood: -2962.87 (per sample: -1.481)
[subject] Fitting time: 126.88 secs
Type 2 level finished (211.7 secs)
<remeta.model.ReMeta at 0x7ceab31016e0>Let’s check out the parameters:
result = rem.summary()
for k, v in result.params.items():
print(f'{k}: {np.array2string(np.array(v), precision=3)}')type1_noise: 0.518
type2_noise: 0.312
type2_criteria: [0.272 0.498 0.732]
The fit is still good, although we note that the estimate of type 1 noise is slightly worse. In the output, we also see that the negative log-likelihood for the type 1 stage is significantly worse (692.61) than in the model that included a bias (683.64).