Type 1: the decision making stage
Confidence is regarded as a metacognitive variable and thus identifies as a mental representation of another mental representation. In the case of confidence, the other mental representation is the decision variable that guided our original decision about which we are about to express a sense of confidence. As a consequence, a good model of confidence needs to model the construction of the decision variable — the type 1 stage — as precisely as possible.
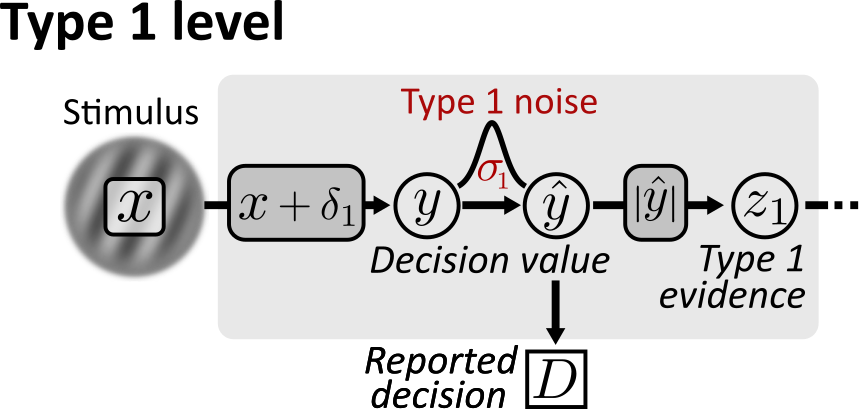
Central to the type 1 stage is the psychometric function which describes the relationship between the stimulus variable and choice probability for the positive stimulus category . By default, ReMeta uses a Gaussian type 1 noise model:
The default psychometric curve in ReMeta is characterized by two parameters, , which reflects type 1 noise, and , which reflects the type 1 bias.
In addition, ReMeta includes a threshold parameter, representing a minimal stimulus intensity that is required to drive any response in the observer:
For ReMeta’s method to work, – corresponding to the absolute value of stimuli which is passed to the fit methods – must encode stimulus evidence. To make sure that your stimuli encode stimulus evidence, check out the dedicated section on Stimulus evidence.
The following sections describe the type 1 parameters available in ReMeta.
Default parameters¶
Type 1 noise¶
| Parameter | Symbol | How to enable | Default | Possible values |
|---|---|---|---|---|
type1_noise | cfg.param_type1_noise.enable = True | True | True |
In ReMeta, type 1 noise reflects noise that is present either in the stimulus or in the decision process. The associated parameter reflects the standard deviation of the underlying type 1 noise process. Lower means lower stimulus/decision noise, hence a more sensitive observer and a steeper psychometric curve. Higher means higher stimulus/decision noise, hence a less sensitive observer and a flatter psychometric curve.
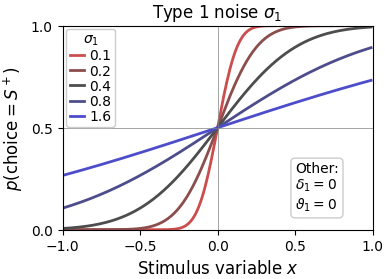
Every ReMeta model must fit type1 noise, hence it cannot be disabled. However, ReMeta allows separate type 1 noise estimates for the two stimulus categories by setting cfg.param_type1_noise.asym = True. See below for an example of a psychometric curve with stimulus-category-dependent type 1 noise.
remeta.plot_psychometric(type1_noise=[0.5, 0.2])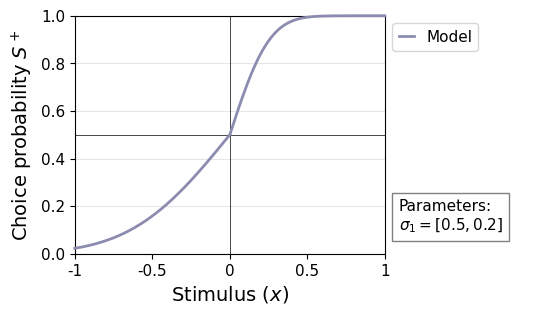
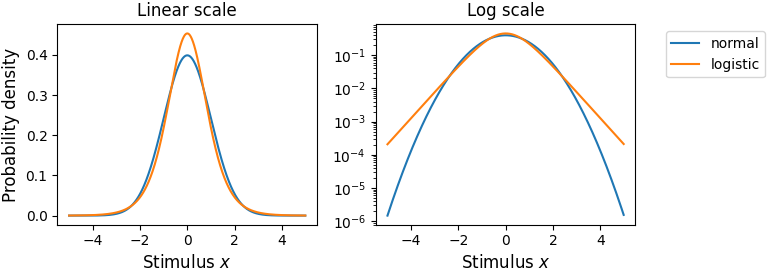
By default, the type 1 model assumes a normal distribution for type 1 noise (cfg.param_type1_noise.model = 'normal'). However, for some decisional processes a logistic noise model may be more approprtiate cfg.param_type1_noise.model = 'logistic'.
To appreciate the difference between normal and logistic noise models, consider a random dot kinematogram in which observers have to judge whether the dominant direction of motion is left or right. Is observers choose the direction of motion based on the difference between the average response of right-tuned versus the average response of left-tuned neurons, then a normal noise model would typically be appropriate.
If they choose the direction based on the maximum response of right-tuned versus the maximum response of left-tuned neurons, then a logistic noise model may be more appropriate.
The logistic distribution (kurtosis 4.2) is is tail-heavier than the normal distribution (kurtosis 3):
Type 1 bias¶
| Parameter | Symbol | How to enable | Default | Possible values |
|---|---|---|---|---|
type1_bias | cfg.param_type1_bias.enable = True | True | False, True |
The type 1 bias may either be perceptual or decisional in nature and leads to a horizontal shift of the psychometric function. A negative bias indicates a preference for and thus a right-ward shift of the curve. A positive bias indicates a preference for and thus a left-ward shift of the curve.
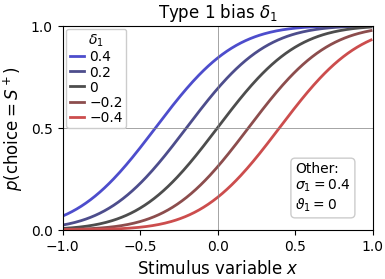
Note that while setting cfg.param_type1_bias.asym = True, i.e. different biases per stimulus category, is theoretically possible, it is discouraged, as it defeats the interpretation of a bias parameter and leads to a discontinuity at the stimulus boundary.
Additional parameters¶
Type 1 threshold¶
| Parameter | Symbol | How to enable | Default | Possible values |
|---|---|---|---|---|
type1_thresh | cfg.param_type1_thresh.enable = True | True | False, True |
A threshold parameter describes the minimum amount of evidence to elicit any change in choice probability. It is not enabled by default and is mostly useful if an experiment includes many stimuli around the threshold of conscious awareness.
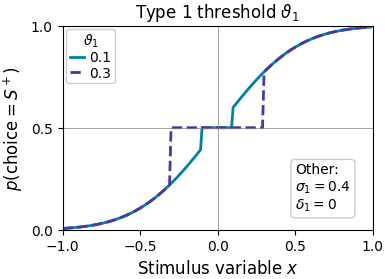
Type 1 thresholds can be fitted per stimulus category (cfg.param_type1_thresh.asym = True). See below for an example of an associated psychometric curve.
remeta.plot_psychometric(type1_noise=0.5, type1_thresh=[0.1, 0.2])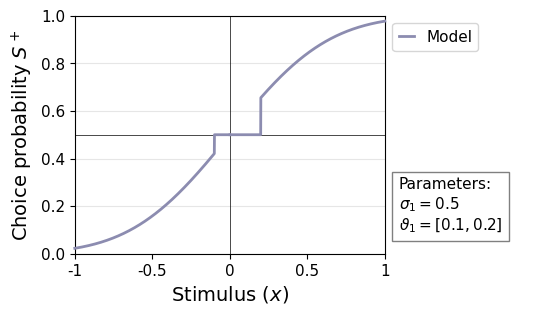
Type 1 nonlinear encoding¶
| Parameter | Symbol | How to enable | Default | Possible values |
|---|---|---|---|---|
type1_nonlinear_gain | cfg.param_type1_nonlinear_gain.enable = True | False | False, True | |
type1_nonlinear_scale | cfg.param_type1_nonlinear_scale.enable = True | False | False, True |
Most models of binary choices assume a linear relationship between stimulus intensity as defined by the modeler and stimulus intensity as encoded in the nervous system. While this assumption is certainly not warranted, from a pragmatic standpoint it is understandable. Not because of a lack of formalism, but due to the fact that the loss of information through binary choices makes an estimate of underlying nonlinearities a daunting task.
Nevertheless, in ReMeta, nonlinearities can be accouted for with two parameters, type1_nonlinear_gain () and type1_nonlinear_scale ():
The chosen nonlinearity has a few favorable properties, including the fact that it’s first derivative equals 1 at (i.e. it does not change the sensitivity of the psychometric function) and it is approximately linear for small . See below for the effects of both nonlinearity parameters.
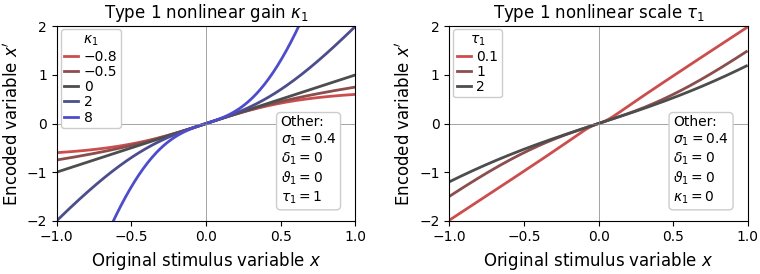
A few practical recommendations:
For most scenarios, leave these parameters disabled. Both parameters require very large numbers of samples to yield sufficiently precise estimates.
If you consider modeling nonlinearities, we recommend to only fit the gain parameter (i.e.
cfg.param_type1_nonlinear_gain.enable = True). In this case, the scale parameter set to the maximum stimulus intensity by default. To change the default scale parameter, usecfg.param_type1_nonlinear_scale.default.If you consider modeling nonlinearities, we strongly recommend to fit these parameters as group parameters to utilize as many samples as possible. Even with 2000 samples per observer, both parameter estimates will be all over the place.